{"title":"A scalable tool for analyzing genomic variants of humans using knowledge graphs and graph machine learning.","authors":"Shivika Prasanna, Ajay Kumar, Deepthi Rao, Eduardo J Simoes, Praveen Rao","doi":"10.3389/fdata.2024.1466391","DOIUrl":null,"url":null,"abstract":"<p><p>Advances in high-throughput genome sequencing have enabled large-scale genome sequencing in clinical practice and research studies. By analyzing genomic variants of humans, scientists can gain better understanding of the risk factors of complex diseases such as cancer and COVID-19. To model and analyze the rich genomic data, knowledge graphs (KGs) and graph machine learning (GML) can be regarded as enabling technologies. In this article, we present a scalable tool called VariantKG for analyzing genomic variants of humans modeled using KGs and GML. Specifically, we used publicly available genome sequencing data from patients with COVID-19. VariantKG extracts variant-level genetic information output by a variant calling pipeline, annotates the variant data with additional metadata, and converts the annotated variant information into a KG represented using the Resource Description Framework (RDF). The resulting KG is further enhanced with patient metadata and stored in a scalable graph database that enables efficient RDF indexing and query processing. VariantKG employs the Deep Graph Library (DGL) to perform GML tasks such as node classification. A user can extract a subset of the KG and perform inference tasks using DGL. The user can monitor the training and testing performance and hardware utilization. We tested VariantKG for KG construction by using 1,508 genome sequences, leading to 4 billion RDF statements. We evaluated GML tasks using VariantKG by selecting a subset of 500 sequences from the KG and performing node classification using well-known GML techniques such as GraphSAGE, Graph Convolutional Network (GCN) and Graph Transformer. VariantKG has intuitive user interfaces and features enabling a low barrier to entry for KG construction, model inference, and model interpretation on genomic variants of humans.</p>","PeriodicalId":52859,"journal":{"name":"Frontiers in Big Data","volume":"7 ","pages":"1466391"},"PeriodicalIF":2.4000,"publicationDate":"2025-01-21","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11790625/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Frontiers in Big Data","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.3389/fdata.2024.1466391","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/1/1 0:00:00","PubModel":"eCollection","JCR":"Q3","JCRName":"COMPUTER SCIENCE, INFORMATION SYSTEMS","Score":null,"Total":0}
引用次数: 0
Abstract
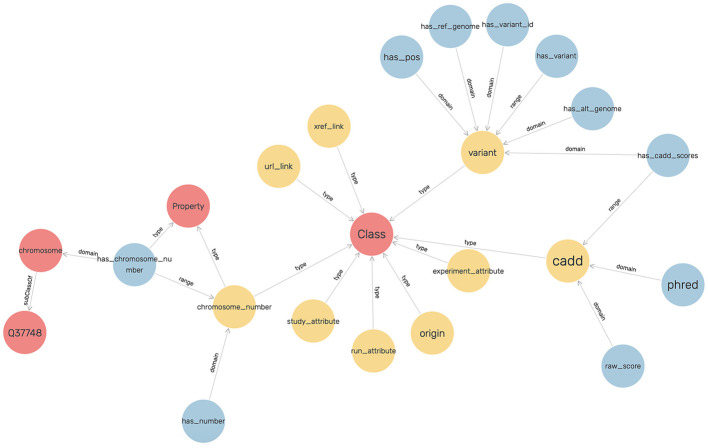
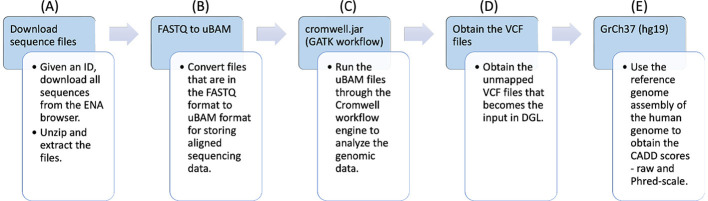
Advances in high-throughput genome sequencing have enabled large-scale genome sequencing in clinical practice and research studies. By analyzing genomic variants of humans, scientists can gain better understanding of the risk factors of complex diseases such as cancer and COVID-19. To model and analyze the rich genomic data, knowledge graphs (KGs) and graph machine learning (GML) can be regarded as enabling technologies. In this article, we present a scalable tool called VariantKG for analyzing genomic variants of humans modeled using KGs and GML. Specifically, we used publicly available genome sequencing data from patients with COVID-19. VariantKG extracts variant-level genetic information output by a variant calling pipeline, annotates the variant data with additional metadata, and converts the annotated variant information into a KG represented using the Resource Description Framework (RDF). The resulting KG is further enhanced with patient metadata and stored in a scalable graph database that enables efficient RDF indexing and query processing. VariantKG employs the Deep Graph Library (DGL) to perform GML tasks such as node classification. A user can extract a subset of the KG and perform inference tasks using DGL. The user can monitor the training and testing performance and hardware utilization. We tested VariantKG for KG construction by using 1,508 genome sequences, leading to 4 billion RDF statements. We evaluated GML tasks using VariantKG by selecting a subset of 500 sequences from the KG and performing node classification using well-known GML techniques such as GraphSAGE, Graph Convolutional Network (GCN) and Graph Transformer. VariantKG has intuitive user interfaces and features enabling a low barrier to entry for KG construction, model inference, and model interpretation on genomic variants of humans.





 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
