Pub Date : 2024-04-01DOI: 10.1017/s0266466624000082
ZHISHUI HU, IOANNIS KASPARIS, QIYING WANG
We consider local level and local linear estimators for estimation and inference in time-varying parameter (TVP) regressions with general stationary covariates. The latter estimator also yields estimates for parameter derivatives that are utilized for the development of time invariance tests for the regression coefficients. Our theoretical framework is general enough to allow for a wide range of stationary regressors, including stationary long memory. We demonstrate that neglecting time variation in the regression parameters has a range of adverse effects in inference, in particular, when regressors exhibit long-range dependence. For instance, parametric tests diverge under the null hypothesis when the memory order is strictly positive. The finite sample performance of the methods developed is investigated with the aid of a simulation experiment. The proposed methods are employed for exploring the predictability of SP500 returns by realized variance. We find evidence of time variability in the intercept as well as episodic predictability when realized variance is utilized as a predictor in TVP specifications.
{"title":"TIME-VARYING PARAMETER REGRESSIONS WITH STATIONARY PERSISTENT DATA","authors":"ZHISHUI HU, IOANNIS KASPARIS, QIYING WANG","doi":"10.1017/s0266466624000082","DOIUrl":"https://doi.org/10.1017/s0266466624000082","url":null,"abstract":"<p>We consider local level and local linear estimators for estimation and inference in time-varying parameter (TVP) regressions with general stationary covariates. The latter estimator also yields estimates for parameter derivatives that are utilized for the development of time invariance tests for the regression coefficients. Our theoretical framework is general enough to allow for a wide range of stationary regressors, including stationary long memory. We demonstrate that neglecting time variation in the regression parameters has a range of adverse effects in inference, in particular, when regressors exhibit long-range dependence. For instance, parametric tests diverge under the null hypothesis when the memory order is strictly positive. The finite sample performance of the methods developed is investigated with the aid of a simulation experiment. The proposed methods are employed for exploring the predictability of SP500 returns by realized variance. We find evidence of time variability in the intercept as well as episodic predictability when realized variance is utilized as a predictor in TVP specifications.</p>","PeriodicalId":49275,"journal":{"name":"Econometric Theory","volume":"34 1","pages":""},"PeriodicalIF":0.8,"publicationDate":"2024-04-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":null,"resultStr":null,"platform":"Semanticscholar","paperid":"140567820","PeriodicalName":null,"FirstCategoryId":null,"ListUrlMain":null,"RegionNum":4,"RegionCategory":"经济学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":"","EPubDate":null,"PubModel":null,"JCR":null,"JCRName":null,"Score":null,"Total":0}
Pub Date : 2024-03-26DOI: 10.1017/s0266466624000070
Philipp Hermann, Hajo Holzmann
We consider linear random coefficient regression models, where the regressors are allowed to have a finite support. First, we investigate identification, and show that the means and the variances and covariances of the random coefficients are identified from the first two conditional moments of the response given the covariates if the support of the covariates, excluding the intercept, contains a Cartesian product with at least three points in each coordinate. We also discuss identification of higher-order mixed moments, as well as partial identification in the presence of a binary regressor. Next, we show the variable selection consistency of the adaptive LASSO for the variances and covariances of the random coefficients in finite and moderately high dimensions. This implies that the estimated covariance matrix will actually be positive semidefinite and hence a valid covariance matrix, in contrast to the estimate arising from a simple least squares fit. We illustrate the proposed method in a simulation study.
{"title":"BOUNDED SUPPORT IN LINEAR RANDOM COEFFICIENT MODELS: IDENTIFICATION AND VARIABLE SELECTION","authors":"Philipp Hermann, Hajo Holzmann","doi":"10.1017/s0266466624000070","DOIUrl":"https://doi.org/10.1017/s0266466624000070","url":null,"abstract":"<p>We consider linear random coefficient regression models, where the regressors are allowed to have a finite support. First, we investigate identification, and show that the means and the variances and covariances of the random coefficients are identified from the first two conditional moments of the response given the covariates if the support of the covariates, excluding the intercept, contains a Cartesian product with at least three points in each coordinate. We also discuss identification of higher-order mixed moments, as well as partial identification in the presence of a binary regressor. Next, we show the variable selection consistency of the adaptive LASSO for the variances and covariances of the random coefficients in finite and moderately high dimensions. This implies that the estimated covariance matrix will actually be positive semidefinite and hence a valid covariance matrix, in contrast to the estimate arising from a simple least squares fit. We illustrate the proposed method in a simulation study.</p>","PeriodicalId":49275,"journal":{"name":"Econometric Theory","volume":"31 1","pages":""},"PeriodicalIF":0.8,"publicationDate":"2024-03-26","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":null,"resultStr":null,"platform":"Semanticscholar","paperid":"140301197","PeriodicalName":null,"FirstCategoryId":null,"ListUrlMain":null,"RegionNum":4,"RegionCategory":"经济学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":"","EPubDate":null,"PubModel":null,"JCR":null,"JCRName":null,"Score":null,"Total":0}
Pub Date : 2024-03-11DOI: 10.1017/s0266466624000057
Fu Ouyang, Thomas Tao Yang
We propose a new approach to the semiparametric analysis of panel data binary choice models with fixed effects and dynamics (lagged dependent variables). The model under consideration has the same random utility framework as in Honoré and Kyriazidou (2000, Econometrica 68, 839–874). We demonstrate that, with additional serial dependence conditions on the process of deterministic utility and tail restrictions on the error distribution, the (point) identification of the model can proceed in two steps, and requires matching only the value of an index function of explanatory variables over time, rather than the value of each explanatory variable. Our identification method motivates an easily implementable, two-step maximum score (2SMS) procedure – producing estimators whose rates of convergence, in contrast to Honoré and Kyriazidou’s (2000, Econometrica 68, 839–874) methods, are independent of the model dimension. We then analyze the asymptotic properties of the 2SMS procedure and propose bootstrap-based distributional approximations for inference. Evidence from Monte Carlo simulations indicates that our procedure performs satisfactorily in finite samples.
{"title":"SEMIPARAMETRIC ESTIMATION OF DYNAMIC BINARY CHOICE PANEL DATA MODELS","authors":"Fu Ouyang, Thomas Tao Yang","doi":"10.1017/s0266466624000057","DOIUrl":"https://doi.org/10.1017/s0266466624000057","url":null,"abstract":"<p>We propose a new approach to the semiparametric analysis of panel data binary choice models with fixed effects and dynamics (lagged dependent variables). The model under consideration has the same random utility framework as in Honoré and Kyriazidou (2000, <span>Econometrica</span> 68, 839–874). We demonstrate that, with additional serial dependence conditions on the process of deterministic utility and tail restrictions on the error distribution, the (point) identification of the model can proceed in two steps, and requires matching only the value of an index function of explanatory variables over time, rather than the value of each explanatory variable. Our identification method motivates an easily implementable, two-step maximum score (2SMS) procedure – producing estimators whose rates of convergence, in contrast to Honoré and Kyriazidou’s (2000, <span>Econometrica</span> 68, 839–874) methods, are independent of the model dimension. We then analyze the asymptotic properties of the 2SMS procedure and propose bootstrap-based distributional approximations for inference. Evidence from Monte Carlo simulations indicates that our procedure performs satisfactorily in finite samples.</p>","PeriodicalId":49275,"journal":{"name":"Econometric Theory","volume":"26 1","pages":""},"PeriodicalIF":0.8,"publicationDate":"2024-03-11","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":null,"resultStr":null,"platform":"Semanticscholar","paperid":"140097691","PeriodicalName":null,"FirstCategoryId":null,"ListUrlMain":null,"RegionNum":4,"RegionCategory":"经济学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":"","EPubDate":null,"PubModel":null,"JCR":null,"JCRName":null,"Score":null,"Total":0}
Pub Date : 2024-03-07DOI: 10.1017/s0266466624000045
Zongwu Cai, Ying Fang, Ming Lin, Shengfang Tang
This paper proposes a nonparametric test to assess whether there exist heterogeneous quantile treatment effects (QTEs) of an intervention on the outcome of interest across different sub-populations defined by covariates of interest. Specifically, a consistent test statistic based on the Cramér–von Mises type criterion is developed to test if the treatment has a constant quantile effect for all sub-populations defined by covariates of interest. Under some regularity conditions, the asymptotic behaviors of the proposed test statistic are investigated under both the null and alternative hypotheses. Furthermore, a nonparametric Bootstrap procedure is suggested to approximate the finite-sample null distribution of the proposed test; then, the asymptotic validity of the proposed Bootstrap test is theoretically justified. Through Monte Carlo simulations, we demonstrate the power properties of the test in finite samples. Finally, the proposed testing approach is applied to investigate whether there exists heterogeneity for the QTE of maternal smoking during pregnancy on infant birth weight across different age groups of mothers.
{"title":"A NONPARAMETRIC TEST OF HETEROGENEITY IN CONDITIONAL QUANTILE TREATMENT EFFECTS","authors":"Zongwu Cai, Ying Fang, Ming Lin, Shengfang Tang","doi":"10.1017/s0266466624000045","DOIUrl":"https://doi.org/10.1017/s0266466624000045","url":null,"abstract":"<p>This paper proposes a nonparametric test to assess whether there exist heterogeneous quantile treatment effects (QTEs) of an intervention on the outcome of interest across different sub-populations defined by covariates of interest. Specifically, a consistent test statistic based on the Cramér–von Mises type criterion is developed to test if the treatment has a constant quantile effect for all sub-populations defined by covariates of interest. Under some regularity conditions, the asymptotic behaviors of the proposed test statistic are investigated under both the null and alternative hypotheses. Furthermore, a nonparametric Bootstrap procedure is suggested to approximate the finite-sample null distribution of the proposed test; then, the asymptotic validity of the proposed Bootstrap test is theoretically justified. Through Monte Carlo simulations, we demonstrate the power properties of the test in finite samples. Finally, the proposed testing approach is applied to investigate whether there exists heterogeneity for the QTE of maternal smoking during pregnancy on infant birth weight across different age groups of mothers.</p>","PeriodicalId":49275,"journal":{"name":"Econometric Theory","volume":"128 1","pages":""},"PeriodicalIF":0.8,"publicationDate":"2024-03-07","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":null,"resultStr":null,"platform":"Semanticscholar","paperid":"140056943","PeriodicalName":null,"FirstCategoryId":null,"ListUrlMain":null,"RegionNum":4,"RegionCategory":"经济学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":"","EPubDate":null,"PubModel":null,"JCR":null,"JCRName":null,"Score":null,"Total":0}
Pub Date : 2024-02-15DOI: 10.1017/s0266466624000033
Oliver Stypka, Martin Wagner, Peter Grabarczyk, Rafael Kawka
Cointegrating polynomial regressions (CPRs) include deterministic variables, integrated variables, and their powers as explanatory variables. Based on a novel kernel-weighted limit result and a novel functional central limit theorem, this paper shows that the fully modified ordinary least squares (FM-OLS) estimator of Phillips and Hansen (1990, Review of Economic Studies 57, 99–125) is robust to being used in CPRs. Being used in CPRs refers to a widespread empirical practice that treats the integrated variables and their powers, incorrectly, as a vector of integrated variables and uses textbook FM-OLS. Robustness means that this “formal” FM-OLS practice leads to a zero mean Gaussian mixture limiting distribution that coincides with the limiting distribution of the Wagner and Hong (2016, Econometric Theory 32, 1289–1315) application of the FM estimation principle to the CPR case. The only restriction for this result to hold is that all integrated variables to power one are included as regressors. Even though simulation results indicate performance advantages of the Wagner and Hong (2016, Econometric Theory 32, 1289–1315) estimator, partly even in large samples, the results of the paper give an asymptotic foundation to “formal” FM-OLS and thus enlarge the usability of the Phillips and Hansen (1990, Review of Economic Studies 57, 99–125) estimator implemented in many software packages.
{"title":"COINTEGRATING POLYNOMIAL REGRESSIONS: ROBUSTNESS OF FULLY MODIFIED OLS","authors":"Oliver Stypka, Martin Wagner, Peter Grabarczyk, Rafael Kawka","doi":"10.1017/s0266466624000033","DOIUrl":"https://doi.org/10.1017/s0266466624000033","url":null,"abstract":"Cointegrating polynomial regressions (CPRs) include deterministic variables, integrated variables, and their powers as explanatory variables. Based on a novel kernel-weighted limit result and a novel functional central limit theorem, this paper shows that the fully modified ordinary least squares (FM-OLS) estimator of Phillips and Hansen (1990, <jats:italic>Review of Economic Studies</jats:italic> 57, 99–125) is robust to being used in CPRs. Being used in CPRs refers to a widespread empirical practice that treats the integrated variables and their powers, incorrectly, as a vector of integrated variables and uses textbook FM-OLS. Robustness means that this “formal” FM-OLS practice leads to a zero mean Gaussian mixture limiting distribution that coincides with the limiting distribution of the Wagner and Hong (2016, <jats:italic>Econometric Theory</jats:italic> 32, 1289–1315) application of the FM estimation principle to the CPR case. The only restriction for this result to hold is that all integrated variables to power one are included as regressors. Even though simulation results indicate performance advantages of the Wagner and Hong (2016, <jats:italic>Econometric Theory</jats:italic> 32, 1289–1315) estimator, partly even in large samples, the results of the paper give an asymptotic foundation to “formal” FM-OLS and thus enlarge the usability of the Phillips and Hansen (1990, <jats:italic>Review of Economic Studies</jats:italic> 57, 99–125) estimator implemented in many software packages.","PeriodicalId":49275,"journal":{"name":"Econometric Theory","volume":"308 1","pages":""},"PeriodicalIF":0.8,"publicationDate":"2024-02-15","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":null,"resultStr":null,"platform":"Semanticscholar","paperid":"139769573","PeriodicalName":null,"FirstCategoryId":null,"ListUrlMain":null,"RegionNum":4,"RegionCategory":"经济学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":"","EPubDate":null,"PubModel":null,"JCR":null,"JCRName":null,"Score":null,"Total":0}
Pub Date : 2024-02-08DOI: 10.1017/s0266466624000021
Chaohua Dong, Yundong Tu
This paper considers semiparametric sieve estimation in high-dimensional single index models. The use of Hermite polynomials in approximating the unknown link function provides a convenient framework to conduct both estimation and variable selection. The estimation of the index parameter is formulated from solutions obtained by the routine penalized weighted linear regression procedure, where the weights are used in order to tackle the unbounded support of the regressors. The resulting index parameter estimator is shown to be consistent and sparse, and the asymptotic normality for the estimators of both the index parameter and the link function is established. To perform variable selection in the ultra-high dimension case, we further suggest a forward regression screening method, which is shown to enjoy the sure independence screening property. This screening procedure can be used before the penalized variable selection to reduce the burden of dimensionality. Numerical results show that both the variable selection procedures and the associated estimators perform well in finite samples.
{"title":"SEMIPARAMETRIC ESTIMATION AND VARIABLE SELECTION FOR SPARSE SINGLE INDEX MODELS IN INCREASING DIMENSION","authors":"Chaohua Dong, Yundong Tu","doi":"10.1017/s0266466624000021","DOIUrl":"https://doi.org/10.1017/s0266466624000021","url":null,"abstract":"This paper considers semiparametric sieve estimation in high-dimensional single index models. The use of Hermite polynomials in approximating the unknown link function provides a convenient framework to conduct both estimation and variable selection. The estimation of the index parameter is formulated from solutions obtained by the routine penalized weighted linear regression procedure, where the weights are used in order to tackle the unbounded support of the regressors. The resulting index parameter estimator is shown to be consistent and sparse, and the asymptotic normality for the estimators of both the index parameter and the link function is established. To perform variable selection in the ultra-high dimension case, we further suggest a forward regression screening method, which is shown to enjoy the sure independence screening property. This screening procedure can be used before the penalized variable selection to reduce the burden of dimensionality. Numerical results show that both the variable selection procedures and the associated estimators perform well in finite samples.","PeriodicalId":49275,"journal":{"name":"Econometric Theory","volume":"5 1","pages":""},"PeriodicalIF":0.8,"publicationDate":"2024-02-08","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":null,"resultStr":null,"platform":"Semanticscholar","paperid":"139769564","PeriodicalName":null,"FirstCategoryId":null,"ListUrlMain":null,"RegionNum":4,"RegionCategory":"经济学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":"","EPubDate":null,"PubModel":null,"JCR":null,"JCRName":null,"Score":null,"Total":0}
Pub Date : 2024-01-26DOI: 10.1017/s026646662400001x
Andrii Babii, Jean-Pierre Florens
It is common to assume in empirical research that observables and unobservables are additively separable, especially when the former are endogenous. This is because it is widely recognized that identification and estimation challenges arise when interactions between the two are allowed for. Starting from a nonseparable IV model, where the instrumental variable is independent of unobservables, we develop a novel nonparametric test of separability of unobservables. The large-sample distribution of the test statistics is nonstandard and relies on a Donsker-type central limit theorem for the empirical distribution of nonparametric IV residuals, which may be of independent interest. Using a dataset drawn from the 2015 U.S. Consumer Expenditure Survey, we find that the test rejects the separability in Engel curves for some commodities.
在实证研究中,通常假定可观测变量和不可观测变量是可加分离的,尤其是当前者是内生变量时。这是因为人们普遍认为,如果允许两者之间存在交互作用,就会出现识别和估计难题。从工具变量独立于非观测变量的非分离 IV 模型出发,我们开发了一种新的非参数非观测变量可分性检验方法。检验统计量的大样本分布是非标准的,依赖于非参数 IV 残差经验分布的 Donsker 型中心极限定理,这可能会引起独立的兴趣。利用 2015 年美国消费者支出调查的数据集,我们发现该检验拒绝了某些商品的恩格尔曲线可分性。
{"title":"ARE UNOBSERVABLES SEPARABLE?","authors":"Andrii Babii, Jean-Pierre Florens","doi":"10.1017/s026646662400001x","DOIUrl":"https://doi.org/10.1017/s026646662400001x","url":null,"abstract":"It is common to assume in empirical research that observables and unobservables are additively separable, especially when the former are endogenous. This is because it is widely recognized that identification and estimation challenges arise when interactions between the two are allowed for. Starting from a nonseparable IV model, where the instrumental variable is independent of unobservables, we develop a novel nonparametric test of separability of unobservables. The large-sample distribution of the test statistics is nonstandard and relies on a Donsker-type central limit theorem for the empirical distribution of nonparametric IV residuals, which may be of independent interest. Using a dataset drawn from the 2015 U.S. Consumer Expenditure Survey, we find that the test rejects the separability in Engel curves for some commodities.","PeriodicalId":49275,"journal":{"name":"Econometric Theory","volume":"64 1","pages":""},"PeriodicalIF":0.8,"publicationDate":"2024-01-26","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":null,"resultStr":null,"platform":"Semanticscholar","paperid":"139582752","PeriodicalName":null,"FirstCategoryId":null,"ListUrlMain":null,"RegionNum":4,"RegionCategory":"经济学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":"","EPubDate":null,"PubModel":null,"JCR":null,"JCRName":null,"Score":null,"Total":0}
Pub Date : 2024-01-22DOI: 10.1017/s0266466623000385
Han Hong, Jessie Li
We consider inference for possibly misspecified GMM models based on possibly nonsmooth moment conditions. While it is well known that misspecified GMM estimators with smooth moments remain $sqrt {n}$ consistent and asymptotically normal, globally misspecified nonsmooth GMM estimators are $n^{1/3}$ consistent when either the weighting matrix is fixed or when the weighting matrix is estimated at the $n^{1/3}$ rate or faster. Because the estimator’s nonstandard asymptotic distribution cannot be consistently estimated using the standard bootstrap, we propose an alternative rate-adaptive bootstrap procedure that consistently estimates the asymptotic distribution regardless of whether the GMM estimator is smooth or nonsmooth, correctly or incorrectly specified. Monte Carlo simulations for the smooth and nonsmooth cases confirm that our rate-adaptive bootstrap confidence intervals exhibit empirical coverage close to the nominal level.
{"title":"RATE-ADAPTIVE BOOTSTRAP FOR POSSIBLY MISSPECIFIED GMM","authors":"Han Hong, Jessie Li","doi":"10.1017/s0266466623000385","DOIUrl":"https://doi.org/10.1017/s0266466623000385","url":null,"abstract":"<p>We consider inference for possibly misspecified GMM models based on possibly nonsmooth moment conditions. While it is well known that misspecified GMM estimators with smooth moments remain <span><span><img data-mimesubtype=\"png\" data-type=\"\" src=\"https://static.cambridge.org/binary/version/id/urn:cambridge.org:id:binary:20240119130519665-0982:S0266466623000385:S0266466623000385_inline1.png\"><span data-mathjax-type=\"texmath\"><span>$sqrt {n}$</span></span></img></span></span> consistent and asymptotically normal, globally misspecified nonsmooth GMM estimators are <span><span><img data-mimesubtype=\"png\" data-type=\"\" src=\"https://static.cambridge.org/binary/version/id/urn:cambridge.org:id:binary:20240119130519665-0982:S0266466623000385:S0266466623000385_inline2.png\"><span data-mathjax-type=\"texmath\"><span>$n^{1/3}$</span></span></img></span></span> consistent when either the weighting matrix is fixed or when the weighting matrix is estimated at the <span><span><img data-mimesubtype=\"png\" data-type=\"\" src=\"https://static.cambridge.org/binary/version/id/urn:cambridge.org:id:binary:20240119130519665-0982:S0266466623000385:S0266466623000385_inline3.png\"><span data-mathjax-type=\"texmath\"><span>$n^{1/3}$</span></span></img></span></span> rate or faster. Because the estimator’s nonstandard asymptotic distribution cannot be consistently estimated using the standard bootstrap, we propose an alternative rate-adaptive bootstrap procedure that consistently estimates the asymptotic distribution regardless of whether the GMM estimator is smooth or nonsmooth, correctly or incorrectly specified. Monte Carlo simulations for the smooth and nonsmooth cases confirm that our rate-adaptive bootstrap confidence intervals exhibit empirical coverage close to the nominal level.</p>","PeriodicalId":49275,"journal":{"name":"Econometric Theory","volume":"20 1","pages":""},"PeriodicalIF":0.8,"publicationDate":"2024-01-22","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":null,"resultStr":null,"platform":"Semanticscholar","paperid":"139518329","PeriodicalName":null,"FirstCategoryId":null,"ListUrlMain":null,"RegionNum":4,"RegionCategory":"经济学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":"","EPubDate":null,"PubModel":null,"JCR":null,"JCRName":null,"Score":null,"Total":0}
Pub Date : 2024-01-19DOI: 10.1017/s0266466623000403
Shengjie Hong, Liangjun Su, Yaqi Wang
In this paper, we develop methods for statistical inferences in a partially identified nonparametric panel data model with endogeneity and interactive fixed effects. Under some normalization rules, we can concentrate out the large-dimensional parameter vector of factor loadings and specify a set of conditional moment restrictions that are involved with only the finite-dimensional factor parameters along with the infinite-dimensional nonparametric component. For a conjectured restriction on the parameter, we consider testing the null hypothesis that the restriction is satisfied by at least one element in the identified set and propose a test statistic based on a novel martingale difference divergence measure for the distance between a conditional expectation object and zero. We derive a tight asymptotic distributional upper bound for the resultant test statistic under the null and show that it is divergent at rate-N under the global alternative. To obtain the critical values for our test, we propose a version of multiplier bootstrap and establish its asymptotic validity. Simulations demonstrate the finite sample properties of our inference procedure. We apply our method to study Engel curves for major nondurable expenditures in China by using a panel dataset from the China Family Panel Studies.
{"title":"INFERENCE IN PARTIALLY IDENTIFIED PANEL DATA MODELS WITH INTERACTIVE FIXED EFFECTS","authors":"Shengjie Hong, Liangjun Su, Yaqi Wang","doi":"10.1017/s0266466623000403","DOIUrl":"https://doi.org/10.1017/s0266466623000403","url":null,"abstract":"<p>In this paper, we develop methods for statistical inferences in a partially identified nonparametric panel data model with endogeneity and interactive fixed effects. Under some normalization rules, we can concentrate out the large-dimensional parameter vector of factor loadings and specify a set of conditional moment restrictions that are involved with only the finite-dimensional factor parameters along with the infinite-dimensional nonparametric component. For a conjectured restriction on the parameter, we consider testing the null hypothesis that the restriction is satisfied by at least one element in the identified set and propose a test statistic based on a novel martingale difference divergence measure for the distance between a conditional expectation object and zero. We derive a tight asymptotic distributional upper bound for the resultant test statistic under the null and show that it is divergent at rate-<span>N</span> under the global alternative. To obtain the critical values for our test, we propose a version of multiplier bootstrap and establish its asymptotic validity. Simulations demonstrate the finite sample properties of our inference procedure. We apply our method to study Engel curves for major nondurable expenditures in China by using a panel dataset from the China Family Panel Studies.</p>","PeriodicalId":49275,"journal":{"name":"Econometric Theory","volume":"288 1","pages":""},"PeriodicalIF":0.8,"publicationDate":"2024-01-19","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":null,"resultStr":null,"platform":"Semanticscholar","paperid":"139498114","PeriodicalName":null,"FirstCategoryId":null,"ListUrlMain":null,"RegionNum":4,"RegionCategory":"经济学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":"","EPubDate":null,"PubModel":null,"JCR":null,"JCRName":null,"Score":null,"Total":0}
Pub Date : 2024-01-09DOI: 10.1017/s0266466623000397
Yayi Yan, Jiti Gao, Bin Peng
This paper introduces a new class of time-varying vector moving average processes of infinite order. These processes serve dual purposes: (1) they can be used to model time-varying dependence structures, and (2) they can be used to establish asymptotic theories for multivariate time series models. To illustrate these two points, we first establish some fundamental asymptotic properties and use them to infer the trending term of a vector moving average infinity process. We then investigate a class of time-varying VARX models. Finally, we demonstrate the empirical relevance of the theoretical results using extensive simulated and real data studies.
{"title":"ASYMPTOTICS FOR TIME-VARYING VECTOR MA() PROCESSES","authors":"Yayi Yan, Jiti Gao, Bin Peng","doi":"10.1017/s0266466623000397","DOIUrl":"https://doi.org/10.1017/s0266466623000397","url":null,"abstract":"This paper introduces a new class of time-varying vector moving average processes of infinite order. These processes serve dual purposes: (1) they can be used to model time-varying dependence structures, and (2) they can be used to establish asymptotic theories for multivariate time series models. To illustrate these two points, we first establish some fundamental asymptotic properties and use them to infer the trending term of a vector moving average infinity process. We then investigate a class of time-varying VARX models. Finally, we demonstrate the empirical relevance of the theoretical results using extensive simulated and real data studies.","PeriodicalId":49275,"journal":{"name":"Econometric Theory","volume":"52 10 1","pages":""},"PeriodicalIF":0.8,"publicationDate":"2024-01-09","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":null,"resultStr":null,"platform":"Semanticscholar","paperid":"139413289","PeriodicalName":null,"FirstCategoryId":null,"ListUrlMain":null,"RegionNum":4,"RegionCategory":"经济学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":"","EPubDate":null,"PubModel":null,"JCR":null,"JCRName":null,"Score":null,"Total":0}
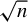
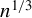
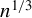
 扫码关注我们
扫码关注我们
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:
